



挖矿这一过程,虽然并没有创造什么实际价值,但挖矿本身维持了比特币系统的稳定。总体来说,比特币系统中的挖矿算法较为成功,并未发现大的漏洞。
The process of mining, while not creating any real value, has itself maintained the stability of the Bitcoin system. Overall, mining algorithms in the Bitcoin system have been successful and no major loopholes have been detected.
当然,比特币系统的挖矿算法也存在一定问题,其中最为突出的就是导致了挖矿设备的专业化,普通计算机用户难以参与进去,导致了挖矿中心化的局面产生,而这与“去中心化”这一理念相违背。
Of course, there are also problems with mining algorithms in the Bitcoin system, most notably the professionalization of mining equipment, which makes it difficult for ordinary computer users to participate, and the centralization of mining, which is contrary to the notion of “decentralization”.
因此,在比特币之后包括以太坊在内的许多加密货币针对该缺陷进行改进,希图做到ASIC Resistance(抗拒ASIC专用矿机)。由于ASIC芯片相对普通计算机来说,算力强但访问内存性能差距不大,因此常用的方法为Memory Hard Mining Puzzle,即增加对内存访问的需求。
As a result, many of the encrypted currencies that followed Bitcoin, including the Taiku, have improved on this deficiency, and Hito has been able to achieve ASIC Resistance (resistance of ASIC-specific machines). Since the ASIC chips are relatively high on normal computers but access to memory performance gaps are small, the commonly used method is Memory Hard Mining Puzzle, i.e. increased demand for memory access .
莱特币曾一度成为市值仅次于比特币的第二大货币。其基本设计大体上和比特币一致,但针对挖矿赛诺菲进行了修改。
At one point, Leytco became the second-largest currency after Bitcoin. Its basic design was broadly identical to that of Bitcoin, but it was modified to deal with the mining of Sanofi.
莱特币的puzzle基于Scrypt。Scrypt为一个对内存性能要求较高的哈希函数,之前多用于计算机安全密码学领域。
Lightcoin’s pizzle is based on Scrypt. Scrypt is a Hashi function that requires a high degree of memory performance and has been used more often in computer security cryptography.
莱特币挖矿算法基本思想
设置一个很大的数组,按照顺序填充伪随机数。
Sets a large array to fill false random numbers in order.
因为哈希函数的输出我们不能提前预料,所以看上去就像是一大堆随机的数据,因此称其为“伪随机数”。
Because we can't predict the output of the Hashi function, it looks like a pile of random data, so it's called a "false random number."
比如有一个Seed为种子节点,通过Seed进行一些运算获得第一个数,之后每个数字都是通过前一个位置的值取哈希得到的。这样填充的特点是:这样的数组中取值存在前后依赖关系。
For example, there is a Seed node, where the first number is obtained by some sort of calculation, and each number is obtained through the value of the previous location. The feature of this filling is that there is a pre- and post-dependency relationship between taking values from such arrays.
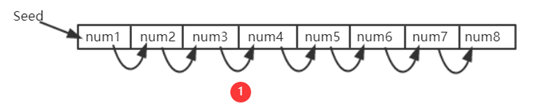
在需要求解Puzzle的时候,按照伪随机顺序,从数组中读取一些数,每次读取位置与前一个数相关。
reads a number from the array in a pseudo-random order when asking for an answer to Puzzle.
例如:第一次,从A位置读取其中数据,根据A中数据计算获得下一次读取位置B;第二次,从B位置读取其中数据,根据B中数据计算获得下一次读取位置C;
For example, for the first time, the data are read from A position, for the next reading position B is calculated from A; for the second time, the data is read from B position, for the next reading position C is calculated from B;
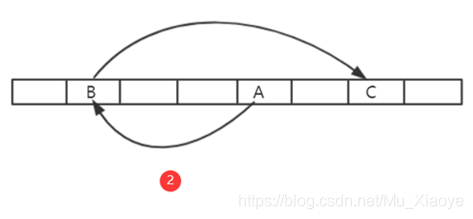

如果数组足够大,对于挖矿矿工来说,就是memory hard,必须保存该数组以便查询,否则每次不仅计算位置,还要根据Seed计算整个数组数据,才能查询到对应位置的数据,这对于矿工来说,挖矿计算复杂度大幅度上升。
If the array is large enough, for miners, it is memory hard, which must be kept in order to search, otherwise the entire array of data must be calculated not only on the location but also on the basis of Seed in order to be able to access the corresponding location data, which for miners is a significant increase in the complexity of mining calculations.
当然,矿工可以选择只保存一部分数据,例如:只保存奇数位置数据,偶数位置需要时再根据前一个奇数位置数据计算即可,从而对内存空间大小减少了一半(计算复杂度提高一点,但内存减少一半)。
Of course, miners can choose to save only part of the data, for example, by saving only odd-numbered location data and calculating even-numbered positions on the basis of the previous odd-numbered location data when required, thereby reducing the size of the memory by one half (calculating a little more complexity, but reducing the memory by one half).
核心思想:不能仅仅进行运算,增加其对内存的访问,从而实现对ASIC芯片不友好。
这个IDEA有问题吗?
看似蛮不错的,使得ASIC矿机挖矿变得不友好,但该方法对Puzzle验证并不是很友好,因为使得求解和验证需要的内存区域是一样大的。想要验证该Puzzle,也需要存储该数组,因此对于轻节点来说,并不友好(系统中绝大多数节点为轻节点)。
It seems rather good, making the ASIC miner mining unfriendly, but the method is not very friendly for the Puzzle verification, because it makes it as large as the memory area needed to solve and verify. To verify the Puzzle, it also needs to store the array, and is therefore unfriendly for light nodes (most of the nodes in the system are light nodes).
因此,莱特币真正应用来说,数组大小不敢设置太大。例如:对于计算机而言,1G毫无压力,而对于手机APP来说,1G占据空间就过大了。所以,实际中,莱特币系统设计的数组大小仅仅128K大小。起初莱特币发行时,不仅希望能够抗拒ASIC,还希望能抗拒GPU。但实际中,后来慢慢出现了GPU挖矿,再后来,ASIC芯片挖矿也出现了。实际应用中,莱特币的设计并未起到预期作用,也就是说,128k对于ASIC Resistance来说过小了。
So, for example: for computers, there is no pressure on 1G, and for mobile phone APP, 1G takes up too much space. So, in practice, the set size of the Letco system was only 128K. When it was released, it wanted not only to resist ASIC, but also to resist GPU. In practice, however, the GPU mine followed, and later, the ASI chip mine. In practical application, the design of Lettco did not work as intended, that is, 128k was too small for ASIC Resistance.
莱特币的这一设计是好事还是坏事?
Is this setup good or bad?
从其并未起到预期作用来看,当然是一件坏事,但换个角度来思考,早期通过宣传这一设计目标,有效吸引了大批矿工参与,解决了莱特币“能启动”问题,因此目前莱特币仍然是一个较为主流的加密货币。
It is certainly a bad thing from the point of view that it did not play its intended role, but from a different perspective, early advocacy of this design objective effectively attracted a large number of miners and solved the problem of the “start-up” of Lettco, so that it is still a more dominant encoded currency.
此外,莱特币和比特币另一区别为出块时间,莱特币为2.5min,为比特币的1/4。除了这些不同外,这两种货币基本一样。
In addition, the other difference between Letcoin and Bitcoin is the time of creation , apart from these differences, the two currencies are basically the same.
以太坊的理念与莱特币相同,都是Memory Hard Mining Puzzle,但具体设计上与莱特币不同。
The idea of Ethio is the same as that of Leitco, which is all Memory Hard Mining Puzzle, but is not specifically designed as that of Leitco.
以太坊挖矿算法基本思想
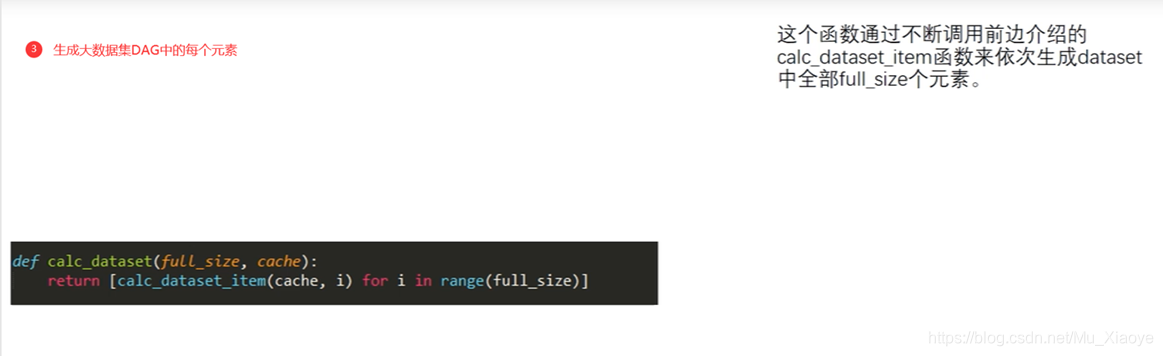
以太坊中,设计了两个数据集,一大一小。小的为16MB的cache,大的数据集为1G的dataset(DAG)。其关系为,1G的数据集是通过16MB数据集生成而来的。
In Ethio, two data sets are designed, one big, one small. The smaller one is a 16MB cache, and the larger one is a 1G dataset (DAG). In relation to this, the 1G data set is generated through a 16MB data set.
思考:为何要设计一大一小两个数据集?
Thinking: Why a big one or two data sets?
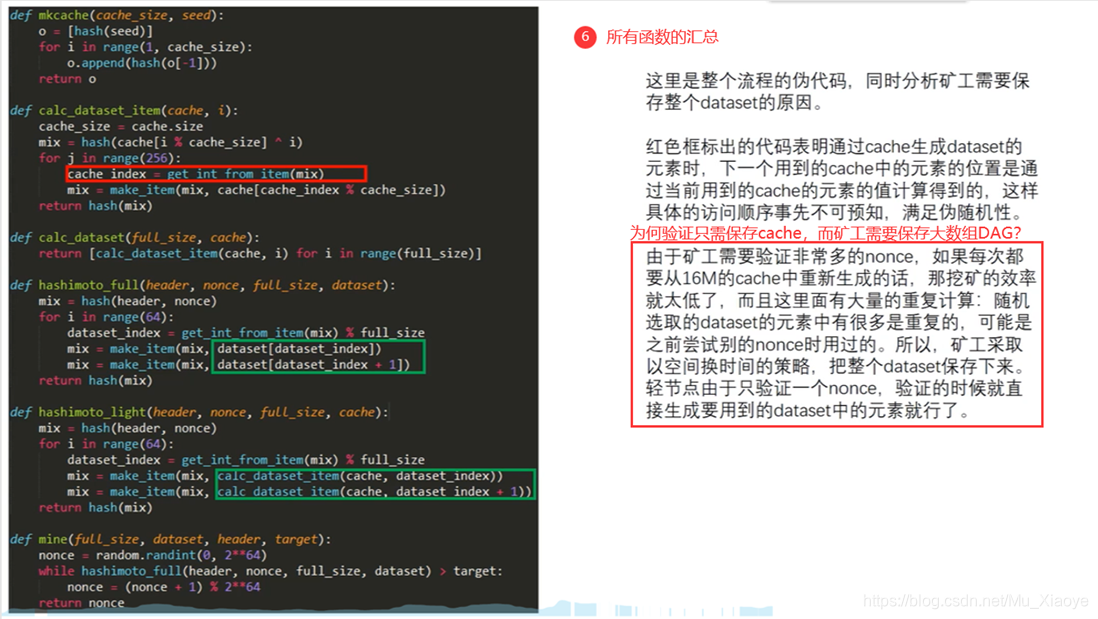
为了便于进行验证,轻节点保存16MB的Cache进行验证即可,而矿工为了挖矿更快,减少重复计算则需要存储1GB大小的大数据集。
In order to facilitate validation, it is sufficient to keep Cache of 16MB in light nodes for validation, while miners need to store a big data set of 1 GB size in order to be able to dig more quickly and reduce double counting.
数据集生成方式
16MB的小Cache数据生成方式与莱特币中生成方式较为类似
16MB's smaller Cache data are generated in a more similar manner to that of the Lightcoin
- 通过Seed进行一些运算获得第一个数,之后每个数字都是通过前一个位置的值取哈希获得的。
- 与莱特币的不同:
- 莱特币:直接从数组中按照伪随机顺序读取一些数据进行运算
- 以太坊:先生成一个更大的数组(注:以太坊中这两个数组大小并不固定,因为考虑到计算机内存不断增大,因此该两个数组需要定期增大)

大的DAG生成方式:大的数组中每个元素都是从小数组中按照伪随机顺序读取一些元素,来回迭代读256次算出一个数,放入大数组中。
Large " strong" DAG generation: Each element in a large array of
如第一次读取A位置数据,对当前哈希值更新迭代算出下一次读取位置B,再进行哈希值更新迭代计算出C位置元素。如此来回迭代读取256次,最终算出一个数作为DAG中第一个元素,如此类推,DAG中每个元素生成方式都依次类推。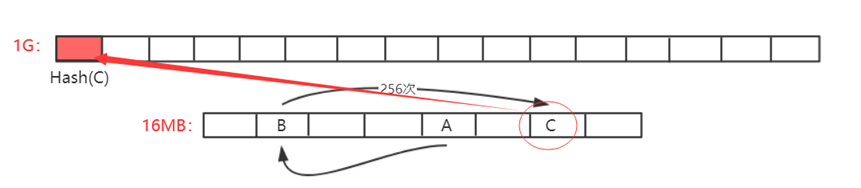
If the A position data is read for the first time, the next reading position B is calculated for the update of the current Hashi value, then the Hashi value is updated for the calculation of the C location element. Thus, 256 repeats, and a number is calculated as the first element in the DAG. If so, each element in the DAG is generated by analogy. 
验证
轻节点只保存小的cache,验证时进行计算即可。
A light node saves only a small cache, which can be calculated at validation.
但对于挖矿来说,如果只保存小的cache,则大部分算力都花费在了通过Cache计算DAG上面,因此,其必须保存大的数组DAG以便于更快挖矿。
For mining, however, if only small cache is preserved, much of the math is spent on calculating DAG through Cache, so that large clusters of DAGs must be preserved to facilitate faster mining.
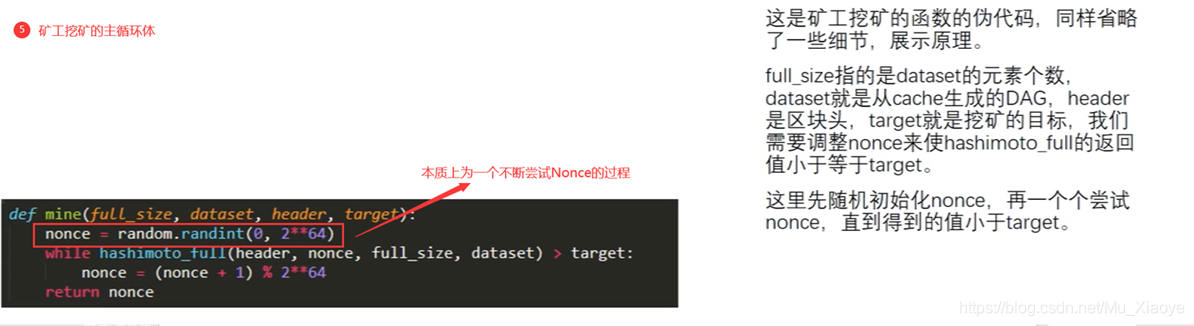
求解puzzle
求解puzzle的时候用的是DAG,cache是不用的,
The solution to Puzzle is with DAG. Cache is not.
根据区块block header和其中的Nonce值计算一个初始哈希,根据其映射到某个初始位置A,读取A位置的数及其相邻的后一个位置A’上的数,根据该两个数进行运算,算得下一个位置B,读取B和B’位置上的数,依次类推,迭代读取64次,共读取128个数。
Calculate an initial Hash based on Block Block Block Block Block Header and its Nonce value, based on its mapping to an initial position A, reading the number of A positions and the number of the later position A'adjacent to it, using these two numbers as the basis for calculating the next position B, reading the number of B and B'positions, by analogy, 64 readings, with a total of 128 readings.
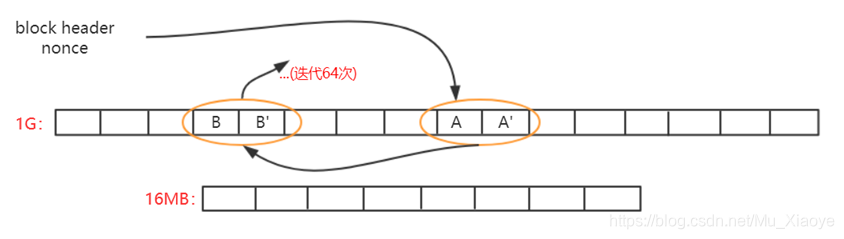

最后,计算出一个哈希值与挖矿难度目标阈值比较,若不符合就重新更换Nonce,重复以上操作直到最终计算哈希值符合难度要求或当前区块已经被挖出。








汇总:
Summary:

目前以太坊挖矿以GPU为主,可见其设计较为成功,这与以太坊设计的挖矿算法(Ethash)所需要的大内存具有很大关系。
The relative success of the current design, which is dominated by the GPU, is very much related to the large memory required by the Ethash / strong method designed by the
1G的大数组与128k相比,差距8000多倍,即使是16MB与128K相比,也大了一百多倍,可见对内存需求的差距很大(况且两个数组大小是会不断增长的)。
The large array of 1G is more than 8,000 times larger than that of 128k, and even 16MB is more than 100 times larger than 128K, indicating a large gap in demand for RAM (and the two arrays are growing in size).
当然,以太坊实现ASIC Resistance除了挖矿算法设计之外,还存在另外一个原因,即其预期从工作量证明(POW)转向权益证明(POS)
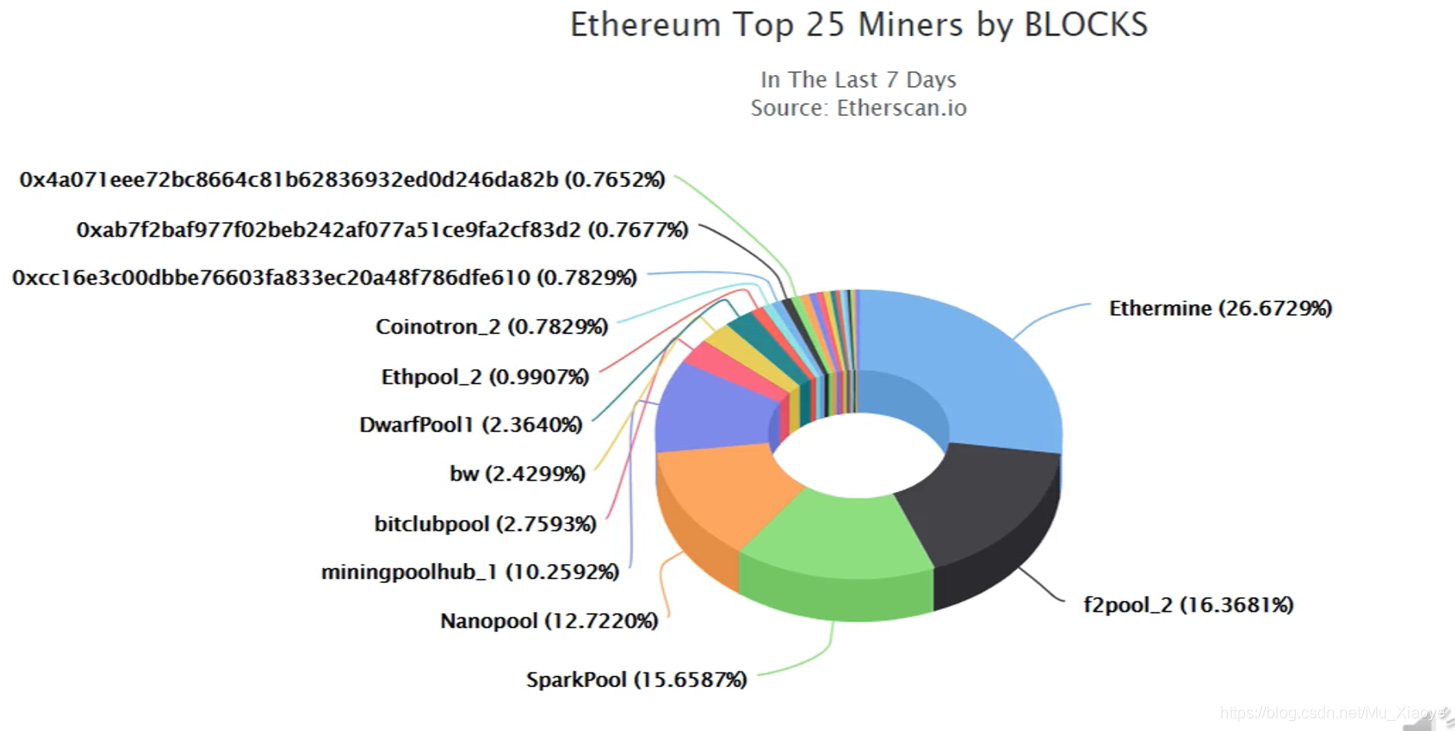
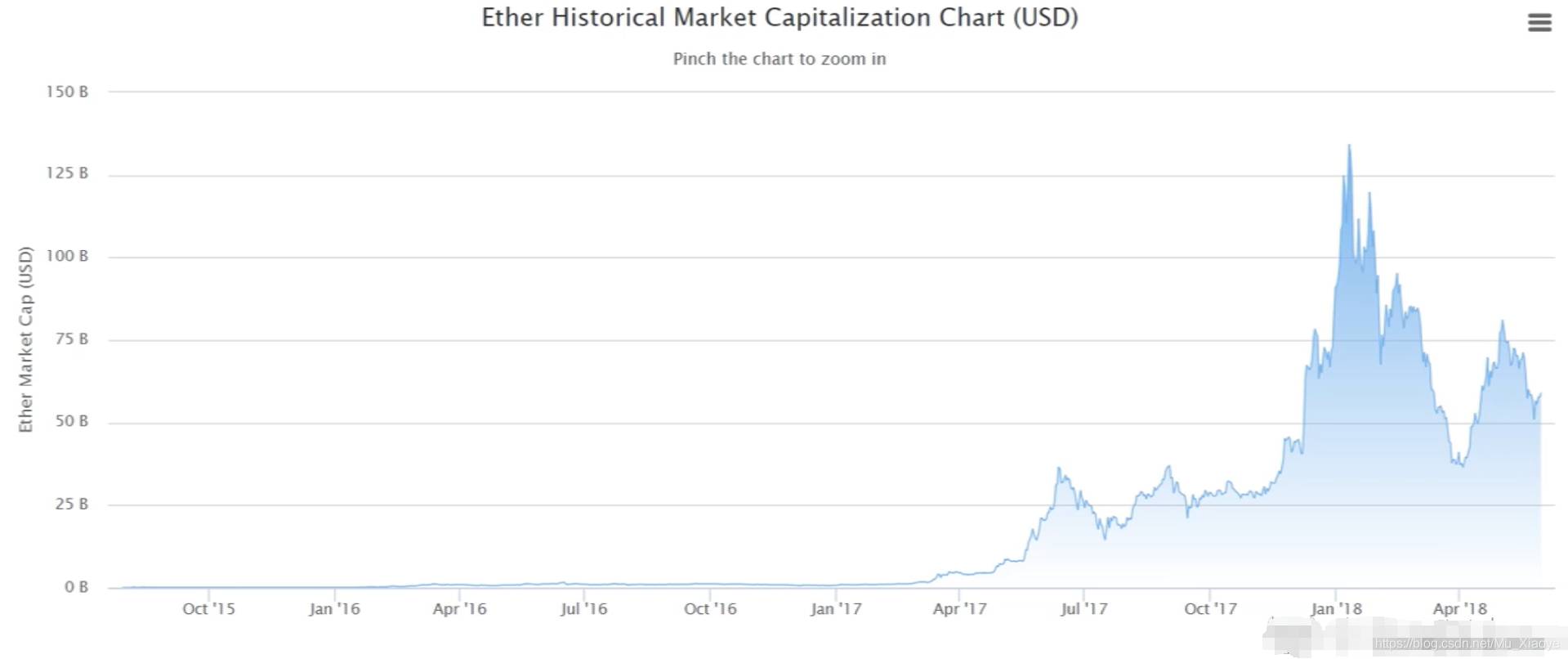
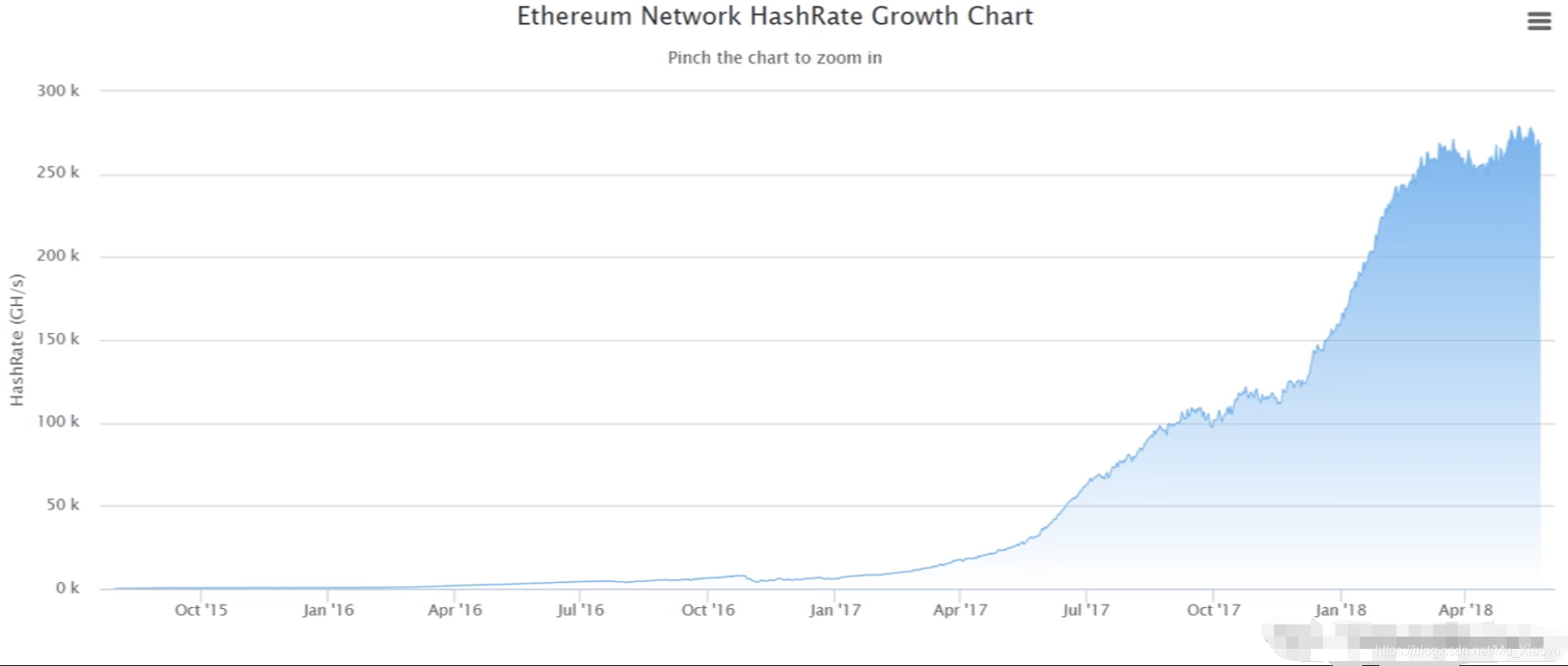
Of course, in addition to the mining algorithm design, there is another reason why the Taiku realization of ASIC Resistance is expected to move from 权益证明:按照所占权益投票进行共识达成,类似股份制有限共识按照股份多少投票,权益证明不需要挖矿。 Evidence of rights and interests: Consensus is reached on the basis of voting on the basis of the rights in question, and consensus on the basis of the number of shares in a limited number of shares, similar to the share system, proves that there is no need for mining. 而这对于ASIC矿机厂商来说,就好比一把悬在头上的达摩克利斯之剑。因为ASIC芯片研发周期很长,成本很高,如果以太坊转入权益证明,这些投入的研发费用将全部白费(ASIC矿机只能用于挖特定的加密货币) And it's like a sword of Damocles hanging over the head of an ASIC miner. Because of the long and costly life cycle of an ASIC chip, the cost of research and development of these inputs would be completely wasted if it were demonstrated by the transfer of interests to the Taiku. 但实际上,以太坊目前仍然是POW挖矿共识机制。在设计之初,以太坊开发者就设想要从POW转向POS,并为了防止有矿工不愿意转埋下了一颗“难度炸弹”。但截至目前,以太坊仍然基于POW共识机制。 But, in reality, Ether is still a Pow mining consensus mechanism. At the beginning of the design, Ether developers conceived a shift from Pow to POS, and in order to prevent miners from willing to transfer a “hard bomb.” To date, however, Ether continues to be based on the Pow consensus mechanism. 以太坊中采用的预挖矿的机制。这里“预挖矿”并不挖矿,而是在开发以太坊时,给开发者预留了一部分货币给开发者。以太坊的早期开发者,目前就很有钱了。 The pre-mining mechanism used in the courtyard. The “pre-mining” here is not a mine, but rather a portion of the money set aside for developers in the development of the courthouse. The early developers of the court are now rich. 而比特币并未采用这一模式,所有比特币都是通过挖矿产生的。但早期挖矿难度容易,所有中本聪本人本来就有很多币(但没花) Bitcoin didn't follow this pattern, and all bitcoin was made from mining. But early mining was difficult, and all Chinese had a lot of coins (but no flowers) 和Pre-Mining对应,还有Pre-Sale,Pre-Sale指的是将预留的货币出售掉用于后续开发,类似于拉风投或众筹。目前,各类加密货币很多,存在一部分货币就在采用Pre-Sale来获取资金,如果此时买入,后续如果该货币取得成功,同样可以获得很大收益,但真正成功的货币只占少数,这就是其风险性。 As with Pre-Mining, and Pre-Sale, Pre-Sale, which refers to the sale of reserved currencies for subsequent development, similar to windfalls or crowds. At present, there are many encrypted currencies of various kinds, and a portion of them are being used by Pre-Sale to obtain funds. If bought at this time, there are also significant gains to be gained if the currency succeeds, but the true success of the currency is only a minority, which is risky. 以太坊中以太币供应量(2018年) There are about 100 million of them, each at a market value of more than $50 billion. 饼状图中,蓝色部分都是Pre-Mining产生的(接近3/4),可见掌握技术有多么重要。黑色部分为出块奖励产生的以太币,绿色为叔父区块产生的奖励以太币 The blue part of the pie is produced by Pre-Mining (approx. 3/4), which shows how important it is to master the technology. The black part is in tats for a piece of reward, and the green for an uncle block is in tats. 最大的25个矿池挖矿算力比重(2018年) 以太币价格变化情况(至2018年) 以太币市值变化情况(至2018年) Changes in market value in Chinese currency (until 2018) 以太币Hash Rate变化情况(至2018年) by the Tails Hash Late (until 2018) 指的是所有矿工加在一起每秒计算的哈希次数。如果不同的加密货币采用的mining puzzle不同,他们的Hash Rate就不能比较,以太坊和比特币不能比较。 This refers to the number of Hashis per second that all miners add up. If different encoded currencies are used differently, their Hash Rate cannot be compared, and in Taiku and Bitcoin cannot be compared. 本篇中挖矿算法设计一直趋向于让大众参与,这一才是公平的。且由于参与人员的分散,算力分散,也进一步使得系统更安全。 It is fair that the mining algorithm design in this section has tended to involve the general public. And the system is further made safer by the fragmentation of the participants and the fragmentation of their numeracy. 但也有人认为让普通计算机参与挖矿是不安全的,像比特币那样,让中心化矿池参与挖矿才是安全的。为什么呢? But it's also argued that it's not safe for 因为要攻击系统,需要购入大量只能进行特定货币挖矿的矿机通过算力进行强行51%攻击,而攻击成功后,必然导致该币种的价值下跌,攻击者投入的硬件成本将会全部打水漂。而如果让通用计算机也参与挖矿,发动攻击成本便大幅度降低,目前的大型互联网公司,将其服务器聚集起来进行攻击即可,而攻击完成后这些服务器仍然可以转而运行日常业务。因此,也有人认为,在挖矿上面,ASIC矿机“一统天下”才是最安全的方式。 If a system is to be attacked, a large number of miners, who can only make a specific currency mine, are required to carry out a force-to-force 51% of the attack, which, after its success, will inevitably lead to a fall in the value of the currency, and the cost of hardware invested by the attackers will be lost. And if a universal computer is also involved in mining, the cost of launching an attack will be significantly reduced, and the current large Internet company will be able to gather its servers and attack them, which, when completed, will still be able to turn into day-to-day operations.
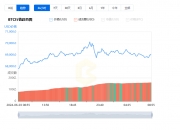
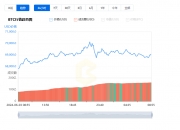
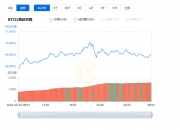
有大约1亿个以太币,每个以太币市值500多亿美元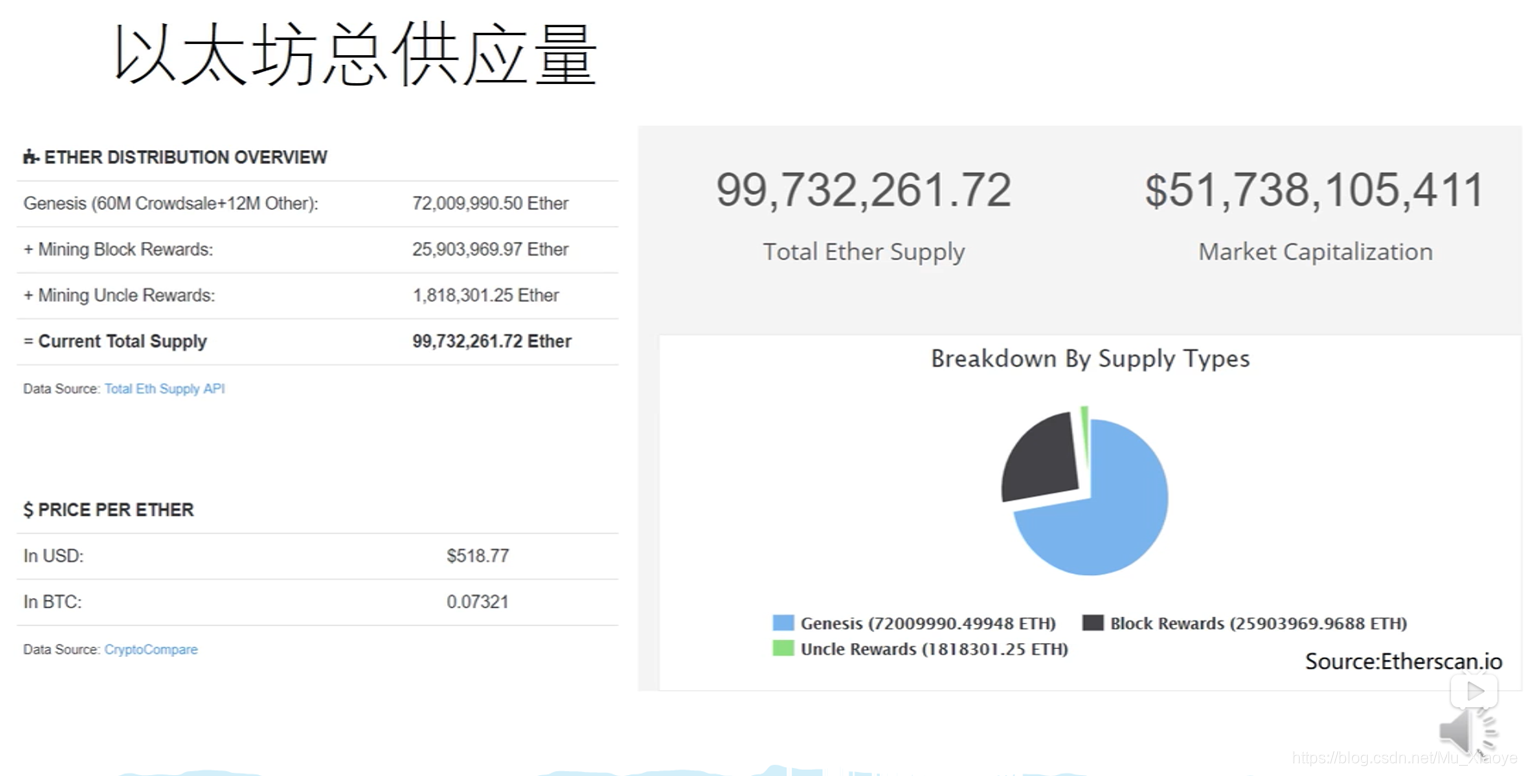


可见,2017年以太坊才开始大涨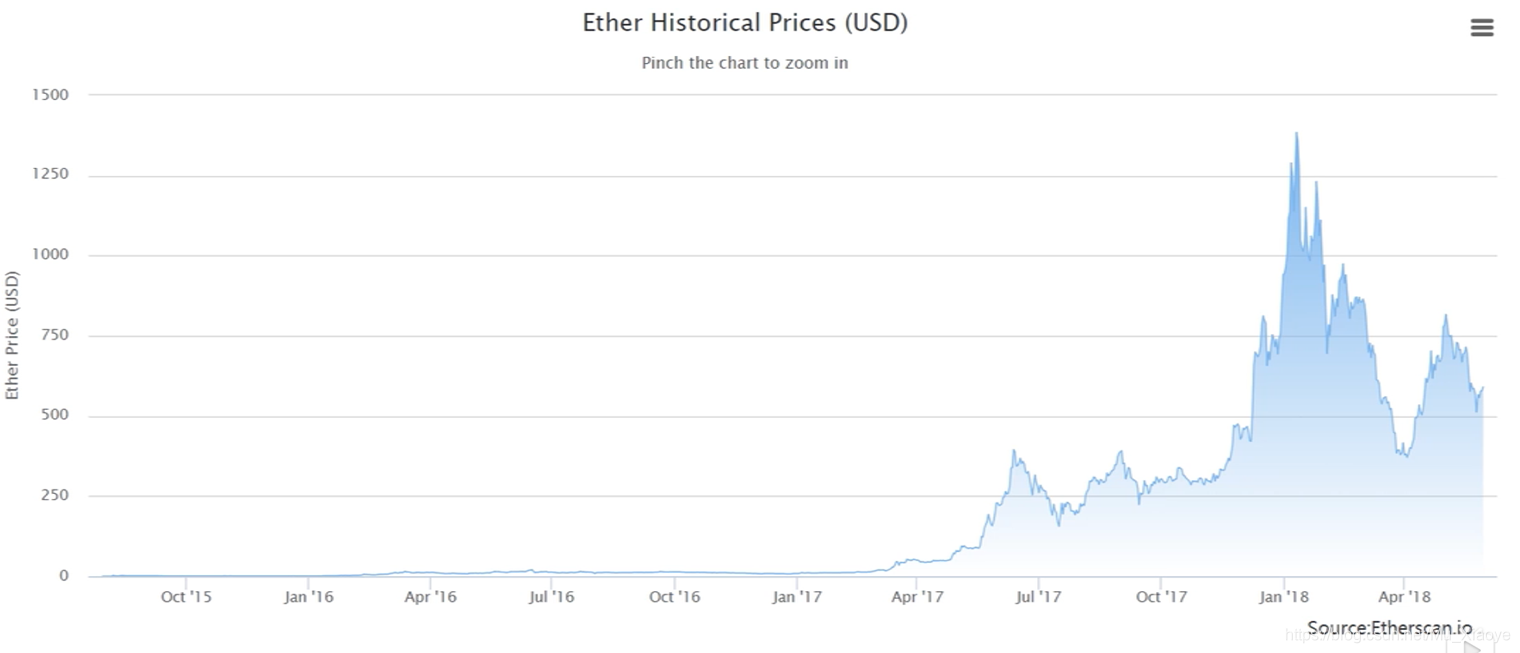
, t_70)

, t_70)
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论